
The honest answer: there is no single best mobile test automation tool
Searching for “best mobile test automation tools” creates the wrong buying motion. Most teams reach that search the same way, after manual testing stops keeping up with the release cadence, so the real question becomes which tools to add, not which single product to crown. There is no single product that wins every situation, because the tools in this market do different jobs. A mobile test automation stack has at least three layers: how tests are authored, where they execute, and which real devices prove the app works outside a lab.
That matters because trust in test results is getting harder to maintain. The Bitrise Mobile Insights 2025 report, drawn from more than 10 million mobile builds, found that the share of teams hitting flaky tests rose from 10 percent in 2022 to 26 percent in 2025, while mobile pipelines grew 23 percent more complex. Google’s engineering teams have reported a similar pattern at their own scale, where roughly 16 percent of tests show some flakiness and managing that flakiness consumes meaningful engineering time.
The point is not that one vendor or one tool fixes all of this. The point is that the wrong stack makes the problem worse. If you choose an authoring tool without thinking about real-device execution, you can end up with tests that are easy to write but hard to trust. If you choose a device cloud without thinking about security, you can end up with a platform your security team will not approve. If you choose a platform without checking that it supports your app’s hardware-dependent features, such as biometrics, camera and sensors, or payments, you can pass tests that never exercise what your users actually do. If you choose only by a ranked list, you can miss the decision that actually controls your release risk.
This guide takes the opposite approach. It separates the market into useful categories, gives you a decision framework, names where common tools fit and where they do not, and goes deeper on real-device sourcing than the typical comparison post. For a QA or engineering leader, the goal is simple: make a stack decision that engineering, security, and finance can all defend.
How this guide compares tools: each one is grouped by the job it does (authoring, execution, device sourcing) and assessed on fit, including where it is the wrong choice, Kobiton included. The criteria reflect what evaluators actually weigh in real selection conversations: app architecture, team skill, CI/CD, and the security and device-sourcing constraints that decide regulated buys. The assessments draw on hands-on use and those evaluation conversations rather than a head-to-head lab benchmark, so treat them as informed guidance, not a scored leaderboard. Where a vendor’s own figure is cited, it is labeled as a vendor claim rather than asserted as fact.
The three categories every best-tools list conflates
The most useful step is to stop treating every product as the same type of tool. Mobile test automation tools fall into three categories that are often compared as if they replace each other. They usually do not.
Frameworks and drivers
Frameworks and drivers are the libraries you author tests against. Appium is the cross-platform standard for native and hybrid apps. Espresso is Android-native. XCUITest and XCTest are the iOS-native equivalents. Maestro is a lightweight YAML-based option. Detox is built around React Native. Playwright is excellent for mobile web and responsive web, but it does not drive native apps, which is the most common category mistake in this market.
Device clouds and execution infrastructure
Device clouds and execution infrastructure are where tests run. This category includes BrowserStack, Sauce Labs, LambdaTest, AWS Device Farm, Firebase Test Lab, Kobiton, Perfecto, and HeadSpin. The real decision is not only which vendor has the broadest catalog. It is whether your app can run on public shared devices, whether you need private dedicated devices, or whether you need on-premise or air-gapped execution. Only a smaller set of platforms, including Perfecto, Kobiton, and HeadSpin, are commonly evaluated when private or dedicated sourcing becomes central.
Authoring-model platforms
Authoring-model platforms change who can create tests and how much code they need to write. Katalon, Tricentis Tosca, ACCELQ, and Autify reduce the coding burden. QA Wolf sells coverage as a managed outcome. Applitools focuses on visual validation. Mabl leans on AI-assisted, low-code authoring with self-healing and maintenance reduction. Both sit in a managed cloud model.
Here is the rule most ranked lists hide: many teams need one tool from the framework or authoring category, plus one from the device-cloud category. The authoring layer decides how the test is expressed. The device layer decides what hardware, OS, network, and security boundary the test runs inside. A connectivity startup evaluating its options framed the point concretely: flows like eSIM activation run through the device’s system settings, so they cannot be exercised on an emulator at all, which is exactly why the execution layer is a separate decision and not an afterthought.
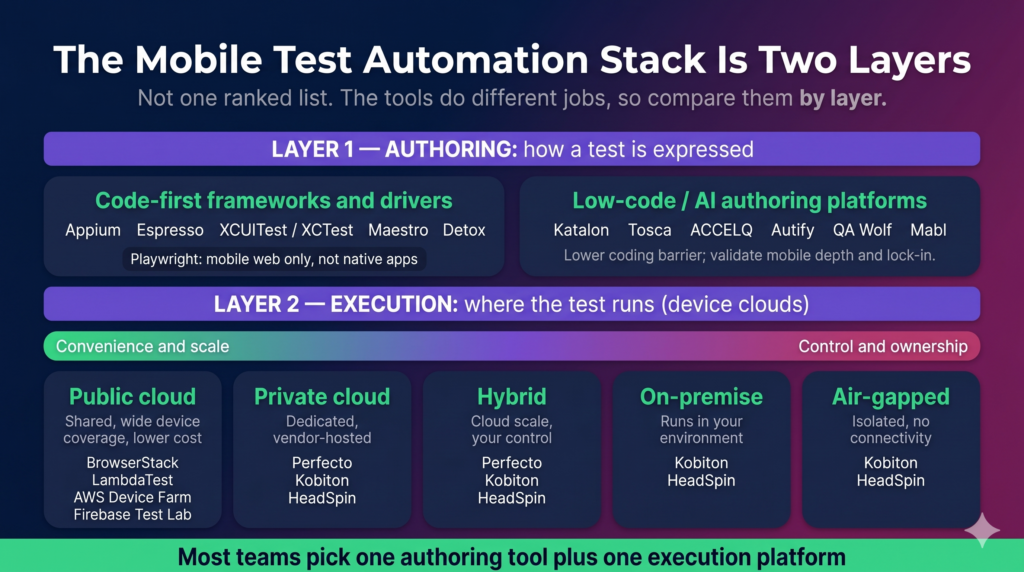
The mobile test automation stack as two layers: authoring plus execution. Most teams pick one of each.
In this grid, Private means a dedicated or private-cloud tier exists; the depth of isolation and regulated-grade control still varies by vendor.
Choose by your situation, not by a ranking: the decision framework
Once the categories are separate, the selection process becomes a sequence of decisions about your environment. Work through these in order.
- App architecture: Android-native, iOS-native, cross-platform native, hybrid, React Native, Flutter, mobile web, or a mix. This is the first filter.
- Test ownership: Developers, SDETs, manual QA, a central quality-engineering team, or a managed service. Ownership determines how much code the tool can expect.
- Authoring model: Code-first, low-code, AI-assisted, AI-native and agentic, or managed outcome. Choose the model your team can sustain, not the one that demos best.
- Execution infrastructure: Emulators, local real devices, public cloud, private dedicated cloud, or on-premise. This determines speed, control, and operational burden.
- Device coverage: Start with your own analytics, then layer in market share, OS adoption, crash data, form factors, geography, and risk-based features.
- CI/CD and triage: Validate parallelism, logs, video, screenshots, device captures, network captures, retries, quarantine, and failure classification. A test that fails without evidence creates work, not confidence.
- Security boundary: App-upload policy, test data, credentials, artifacts, single sign-on, multi-factor, role-based access, audit logs, device cleanup, private network paths, and vendor compliance documentation. For regulated teams this often overrides every other category.
- Total cost: Licenses, device minutes, parallel sessions, private devices, user seats, maintenance labor, CI runtime, device operations, and switching cost.
A tool that fits your app and authoring model but fails your security boundary is still the wrong tool. A tool that is cheap to license but expensive to maintain is not cheap. A tool that looks strong in a demo but cannot produce usable failure evidence will slow down every release. Security-conscious teams often put the priority order plainly: budget is rarely the sticking point, security is, and the first questions from their reviewers are about the SOC 2 report and data handling, not price.
Quick answer: which tools fit which situation
Use this as a starting point, not a final ranking.
| Your situation | Where to start |
| Open-source, cross-platform native or hybrid | Appium |
| Android-native, developer-owned | Espresso |
| iOS-native, developer-owned | XCUITest / XCTest |
| Lightweight mobile-first flows | Maestro |
| React Native end-to-end | Detox |
| Mobile or responsive web | Playwright |
| Public real-device cloud at scale | BrowserStack, Sauce Labs, LambdaTest, Firebase Test Lab, AWS Device Farm |
| Private or dedicated-cloud control for regulated environments | Kobiton, Perfecto, HeadSpin |
| Low-code or codeless enterprise authoring | Katalon, Tosca, ACCELQ, Autify |
| Coverage as a managed outcome | QA Wolf |
Most rows pair with another row. You might use Appium for authoring and a device cloud for execution. You might use Espresso for Android developer-owned tests and still need a real-device platform for release validation. The regulated row is different because device sourcing, data handling, and auditability can determine the rest of the stack.
Tool profiles: where each fits, and where it does not
A useful comparison names the poor fit as clearly as the fit. That is where most vendor pages fall short.
Frameworks and drivers
Appium fits teams that want cross-platform control, broad ecosystem support, and portability across vendors. It is the closest thing to an industry default for native and hybrid app automation. It fits less well when the team wants fast authoring without senior coding skills, because setup, locator strategy, proxy behavior, and maintenance discipline matter. Teams that have run a low-code or Appium suite through a year or two of rapid app change describe the same regret: locators break as the UI structure shifts underneath them, and keeping the suite green becomes a standing cost.
Espresso and XCUITest fit developer-owned native testing. They benefit from native synchronization, tighter platform integration, and early support for new OS behavior. They fit less well when leadership wants one unified cross-platform suite, because the team will maintain separate languages, codebases, and platform-specific expertise.
Maestro fits teams that want readable flows, fast setup, and a lighter syntax for mobile-first scenarios. It fits less well for complex enterprise flows that need heavy branching, advanced data setup, or deep hybrid web-view handling.
Detox fits React Native teams that want end-to-end coverage close to the app framework. It is narrow outside that center of gravity.
Playwright fits mobile web and responsive web. It should not be treated as a native app automation replacement. Browser emulation is useful, but it is not the same as running a native app on real hardware.
Device clouds and execution infrastructure
BrowserStack and Sauce Labs fit teams that need large public cloud access, broad device variety, and straightforward CI integration. BrowserStack advertises one of the largest public clouds, on the order of 20,000 or more real devices and browsers. Both fit less well for air-gapped or no-upload teams when the model requires sending binaries to shared infrastructure. Sauce Labs also offers private device cloud options and a compliance posture that some enterprise teams will evaluate. Teams weighing a switch off these platforms often cite licensing friction as much as capability: paying separately for automation, AI features, and accessibility adds up, and some buyers would rather consolidate into one tool than manage a stack of add-on licenses.
LambdaTest, AWS Device Farm, and Firebase Test Lab fit teams that want accessible execution infrastructure without operating their own device lab. They can be useful for burst capacity, early pipeline coverage, or teams already aligned to those ecosystems. Validate device availability, artifact quality, debugging depth, and how well the service supports your exact app architecture before making it the release gate.
Perfecto and HeadSpin fit regulated or enterprise teams that need public, private, or highly controlled execution. Perfecto runs as a public or private dedicated cloud and stays cloud-connected, so it is a hybrid rather than a true on-premise or air-gapped option. HeadSpin is commonly evaluated where on-premise deployment is part of the requirement. Both can be heavier than necessary if the team only needs basic Appium execution on a public device pool.
Kobiton belongs in the evaluation when real-device control, private or on-premise deployment, device cleanup, a manual-to-automated path, hardware-dependent flows (biometrics, camera and sensor capture, image injection), and deep session diagnostics for debugging (full video, screenshots, device and network logs) matter. Those same diagnostic and coverage strengths are also where Perfecto and HeadSpin are strong, which is why Kobiton should be compared directly against them in regulated or hardware-dependent scenarios rather than positioned as a universal replacement for every team. Its honest poor fit is an early-stage team that only needs free emulator testing and has no real-device, security, or scale pressure. That team should start with open-source frameworks and a free or low-cost execution path, then revisit the device-cloud decision when hardware and compliance start to matter.
Authoring-model platforms
Katalon, Tosca, ACCELQ, and Autify fit teams that need broader test author participation and do not want every test to live in code. Before committing, validate mobile depth, debugging transparency, CI behavior, version control support, and exit flexibility.
Mabl fits teams that want AI-assisted, low-code authoring with auto-healing and reduced test maintenance in a managed cloud model. It is web-first, so for a native iOS or Android program its mobile depth is the thing to validate, because native coverage tends to be shallower than in mobile-first tools. Visual checks are available, but the dedicated visual-validation specialist teams compare against is Applitools. It also fits less well where deep native-device control or on-premise execution is central to the requirement.
QA Wolf fits teams that want coverage as an outcome rather than a tool they operate. QA Wolf publicly claims it can reach 80 percent end-to-end coverage in about four months. Treat that as QA Wolf’s own claim, then validate it against your app complexity, maintenance expectations, data access rules, and exit plan.
One cross-cutting caution: do not over-fit the device matrix to the phones your team personally carries. IDC’s Q1 2026 rankings put Samsung, Apple, Xiaomi, OPPO, and vivo among the top vendors, which is a reminder that release confidence depends on coverage across manufacturers, OS behavior, and regional realities.
Real-device coverage and sourcing: the decision nobody operationalizes
This is where many mobile app testing strategies become real or fall apart. Real devices expose hardware-dependent failures that emulators cannot fully represent: biometrics, Secure Enclave behavior, camera and sensor behavior, battery impact, performance characteristics, carrier conditions, and device-specific OS behavior. Emulators are useful for fast inner-loop development. They are not enough for release confidence. On biometrics in particular, experienced teams stay skeptical of any setup that returns a pass without exercising the real sensor, because bypassing the hardware is not the same as validating the flow a user actually performs.
The first practical question is how much coverage you need. The honest answer is a tiered model rather than a single magic number.
| Tier | Devices | Purpose |
| PR smoke | 1 to 3 devices, at least one real per platform for customer-facing or hardware-dependent apps | fast regression feedback on every change |
| Daily validation | 4 to 8 real | current and N-1 iOS and Android, one low-end Android, one high-value flagship |
| Nightly regression | 8 to 20 real | parallel, sized to your release window, OS policy, and risk |
| Release certification | a broad matrix, often a couple dozen or more real devices | N-2, tablets and foldables, regional makers, accessibility, biometrics, camera, payment, OTP |
| Regulated or high-risk | private, dedicated, or on-premise | audit evidence, data controls, session cleanup, private network path |
For a broad consumer-facing app, the certification set usually runs into the dozens of devices rather than a handful: Perfecto’s Test Coverage Index, for example, sizes roughly 80 percent market coverage at about the top 30 devices, split into essential, enhanced, and extended tiers. Use a benchmark like that to size the list against your real market rather than guessing. The data supports this shape. Worldwide in 2026, Android sits near 70 percent and iOS near 29 percent, while iOS accounts for roughly 64 percent of app spend. Apple reported that as of June 7, 2026, 79 percent of all iPhones and 86 percent of iPhones from the last four years run iOS 26. Those adoption figures are why N, N-1, and N-2 policies should be tied to your users and risk, not copied from another company.
Coverage also needs to reflect how the app is built. Bitrise Mobile Insights 2025 found that 30 percent of mobile builds are non-native, and React Native grew from 63 percent to 83 percent of cross-platform builds. A real matrix accounts for your architecture, the OS versions you support, the devices your users actually hold, and the features that create the most business risk.
The sourcing decision underneath the matrix is even more important. Many teams begin by ruling something out: they do not want to own and operate a rack of physical devices, so cloud sourcing becomes the default and the real question turns to which kind.
Public clouds give speed, variety, and burst capacity. They are often the fastest way to start real-device testing, but they run on shared infrastructure and may not fit sensitive binaries or regulated data.
Private or dedicated clouds give stronger isolation, predictable access, and more control over device state. That matters for stored passcodes, payment wallets, carrier profiles, device settings, and repeatable release validation.
On-premise or air-gapped deployments keep execution inside the organization’s security boundary. That can be necessary when pre-production builds, test data, network traffic, screenshots, videos, or logs cannot leave the environment. The tradeoff is operational responsibility: devices, hubs, networking, upgrades, reservations, cleaning, and uptime all need ownership.
Two patterns recur in evaluations at regulated enterprises. Device coverage is a daily constraint rather than a theoretical one: when a defect reproduces only on a specific OS version, an engineer who lacks that exact device has to track one down before the bug can even be confirmed. And the enterprise environment itself sets limits, because apps wrapped in mobile device management and routed through corporate network controls mean anything that tunnels to a device can trigger a security review before it is allowed.
For regulated teams, these are not abstract preferences. The constraints map to real rules and review processes, including the HIPAA Security Rule, the FTC Health Breach Notification Rule finalized in 2024 and effective July 29, 2024, NYDFS 23 NYCRR 500, and FFIEC and OCC guidance. The vendor conversation should move quickly from features to evidence: SOC 2 Type II, ISO 27001, GDPR, PCI-DSS, data residency, access controls, artifact retention, audit logs, and cleanup policy.
A short discovery checklist usually points to the sourcing model before a feature comparison does:
– Can the binary go to a public cloud? – Can screenshots, videos, logs, or network captures contain regulated data? – Must traffic stay on a private path? – Are rooted or jailbroken devices prohibited? – Are dedicated devices required? – Are single sign-on, multi-factor, role-based access, audit logs, retention, and cleanup mandatory? – Can vendor staff access sessions, artifacts, devices, or logs? – Does the team want to operate devices, or should the vendor operate them?
If those answers push toward private or dedicated-cloud sourcing, the field narrows to platforms built for that model, including Perfecto, Kobiton, and HeadSpin. If you specifically need on-premise deployment, it narrows further to the platforms that run fully inside your boundary, Kobiton and HeadSpin. If the requirement is a fully air-gapped environment with no outside connection, Kobiton is the only one of the platforms compared here that offers it. From there, the evaluation should focus on deployment model, automation compatibility, device operations, security evidence, artifact controls, and how much ownership your team wants to keep.
A note on terms: this guide treats on-premise as the platform and devices running inside your own firewall, and air-gapped as a deployment with no standing external connection. Some platforms market an “air-gapped” or on-premise mode that still keeps a controlled vendor path, such as a VPN tunnel for updates and support; under the strict definition used here, that is isolated-but-connected, not air-gapped.
Use the interactive tool below to turn those questions into a recommended stack for your own situation.
Which mobile test automation stack fits you?
Answer five questions about your app and your constraints. You will get an honest recommendation: an authoring layer plus a device-sourcing model, with the real tools that fit named by name. If you do not need a device cloud yet, this tool will tell you that too.
Here is the stack that fits your answers.
Authoring layer
Device sourcing
Wherever you landed, the fastest way to pressure-test your current setup is to measure it.
AI and agentic mobile app testing in 2026: real capability vs GPT-wrapper hype
AI is the most oversold part of this market, so the useful question is not whether a tool is “AI-powered.” The useful question is what work the AI actually performs, what evidence it produces, and where a human still approves the result.
The 2025-26 World Quality Report, a Capgemini, Sogeti, and OpenText survey of more than 2,000 senior executives, captures the gap. Close to 90 percent of organizations are piloting or deploying generative AI in quality engineering, but only 15 percent have it running at enterprise scale. The barriers cited most often are data privacy at 67 percent, integration complexity at 64 percent, and hallucination and reliability concerns at 60 percent. Interest is high, but enterprise trust is still conditional.
Self-healing is where the language gets muddy. Selector-level self-healing repairs a broken locator when an element changes. That is useful, but it is not the same as understanding the user’s intent. Intent-level self-healing tries to preserve what the step was meant to accomplish when the flow itself changes. That is the more valuable capability, and it is the one to test carefully in a proof of concept.
The reliable enterprise pattern in 2026 is not full autonomy. It is AI-assisted authoring, triage, and healing with human approval where business risk is high. Gartner has predicted that around 33 percent of enterprise apps will integrate agentic AI by 2028, so the direction is clear. Practitioners on complex, frequently released apps are blunt about the real limit: the hard part is whether the AI can hold the app’s context as it changes from release to release, not whether it can generate a script once. The implementation still needs guardrails: version control, review, traceability, explainable changes, controlled test data, and a way to reject a suggested repair.
When a vendor claims agentic mobile app testing, ask for a live failure and repair workflow. Can it explain what changed? Can it show before-and-after evidence? Can it keep the test maintainable? Can you export and own the tests it generates, or are they locked to the platform? Can it run inside your security boundary? Can you approve or reject the change before it becomes part of the suite? Those answers matter more than the label.
Frequently asked questions
What is the best mobile test automation tool overall?
There is no single best tool. The right answer depends on your app architecture, test ownership, CI/CD setup, device coverage, and security boundary. Most teams combine one authoring framework or platform with one device cloud.
What are the best Appium alternatives?
Espresso and XCUITest fit native developer-owned testing. Maestro fits lightweight mobile-first flows. Detox fits React Native. Playwright fits mobile web. Low-code platforms such as Katalon, Tosca, ACCELQ, and Autify fit teams that want broader author participation.
Real devices or emulators?
Use both for different jobs. Emulators are useful for fast development feedback. Real devices are needed for hardware behavior, biometrics, true performance, device-specific defects, and release confidence.
How many devices do I need?
Start with your own analytics and risk profile, then layer in OS adoption, market share, feature risk, and release cadence. A tiered model for smoke, daily, nightly, and certification testing is more defensible than a single number.
Can Playwright test native mobile apps?
No. Playwright is for mobile and responsive web. It does not drive native apps, so it does not replace Appium, Espresso, XCUITest, or a real-device cloud.
When do I need a private or on-premise device cloud?
You need private or on-premise execution when your binary, test data, artifacts, or network traffic cannot leave your security boundary. That is common in banking, healthcare, government, and other regulated environments.
What is self-healing, really?
Selector-level self-healing repairs broken locators. Intent-level self-healing tries to preserve what a test step was meant to accomplish when the flow changes. The second is more valuable, but it needs careful validation.
What are the best AI or agentic testing tools?
Look for tools that can show the work: how tests are authored, how failures are triaged, how repairs are suggested, how humans approve changes, and how everything is audited. Treat full-autonomy claims with caution.
Find your level, then choose your stack
The wrong stack is not a tooling annoyance. It can mean months of migration, pipelines your team does not trust, and a compliance exposure your security team will not accept. The right frame turns “which tool?” into a decision your finance and security leaders can both evaluate: this is the architecture our app requires, this is the evidence it produces, and this is the residual risk we accept.
The fastest way to find where your team sits, and where the next investment should go, is to measure it. Kobiton’s Mobile Maturity Assessment evaluates your testing and DevOps practices and returns a report you can act on.
This guide is part of a series. For the foundation under the device-sourcing argument, see (internal link, added at publish); for how a testing program matures from manual to embedded-in-CI/CD, see (internal link, added at publish). Real-device execution is covered in Kobiton’s real-device testing and mobile automation testing capabilities.